

CSS选择器分类:
| 选择器名称 | 例子 | 说明 |
|---|---|---|
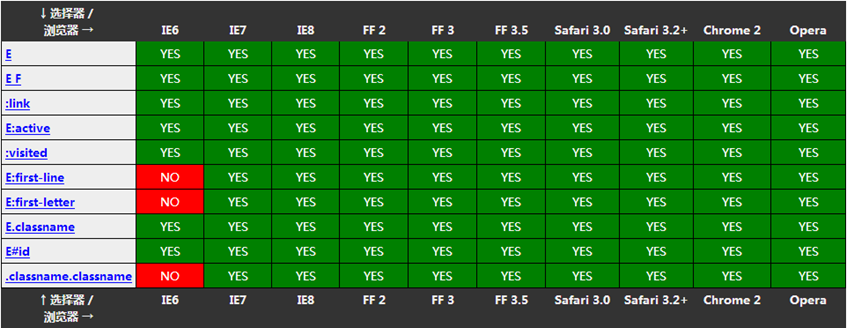
| 元素选择器 | h1,p,span 等 | 最基本的选择器,直接根据标签元素名进行CSS样式设置 |
| 类选择器 | .class选择器名称 | 为元素添加class属性值,并在CSS中利用.class选择器名称进行索引 |
| 结合元素选择器 | p.class选择器名称 | 元素选择器和类选择器结合,例子中可以选择p元素包含的class为class选择器名称的元素;二者之间可以有空格,也可以没有空格 |
| 多类选择器 | .class选择器名称.import | 类选择器与类选择器结合,例子中可以选择class为class选择器名称包含的class为import的元素,二者之间可以有空格,可以没空格 |
| ID选择器 | #class选择器名称 | 为元素添加ID属性值,通过#class选择器名称进行索引,ID选择器具有唯一性,在一个页面中ID不可以重复,ID选择器的属性值区分大小写 |
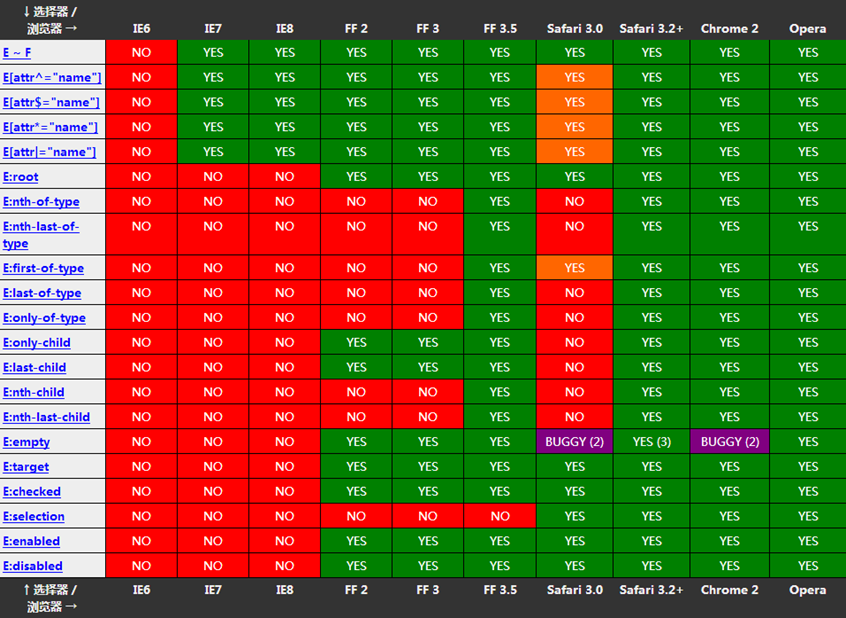
| 简单属性选择器 | *[title],a[href],img[alt] | 根据元素的属性进行选择,例如a标签具有href属性,img标签具有alt属性,并且这些属性还可以有值,如果设置了属性值且是指定元素,使用选择器的时也要添加属性值 |
| 部分属性选择器 | img[alt=~’x’] | 例子中表示选取alt属性值中包含x符号的img元素,~表示字符串中含有后面的属性值 |
| 子串匹配属性选择器 | [x^=’def’],[x$=’def’],[x*=’def] | 分别是选择x的属性值以’def’开头的所有元素,选择x的属性值以’def’结尾的所有元素,选择x的属性值中包含’def’且必须是连着的所有元素 |
| 特定属性选择器 | [x |= ‘def’] | 选择带有’def’开头的属性值的所有元素 |
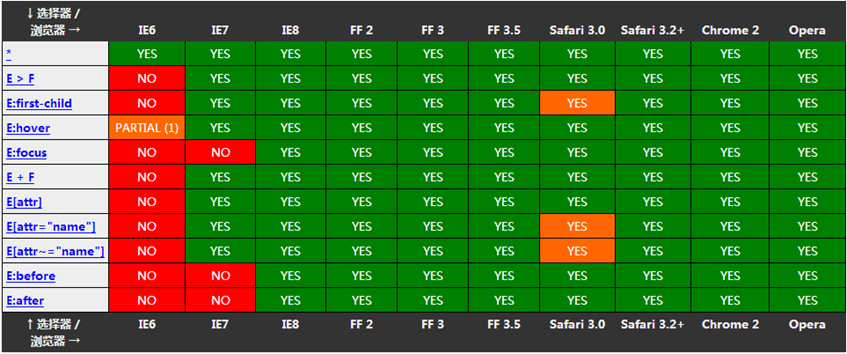
| 后代选择器 | h1 p | 后代选择器又称包含选择器,例子中表示选择h1下面的p元素,不管h1与p之间还有多少层其他元素,如果没有进行特殊设置,将会xuanzeh1下面的所有p元素 |
| 子选择器 | h1>p | 如果不希望选择全部后代元素,只希望选取子元素,则利用>进行选择,例子中表示选择h1下面的p元素,而这个p元素只能是h1的子元素,即二者是父子关系 |
| 相邻兄弟选择器 | h1+p | 相邻兄弟选择器,二者的父元素为同一元素,且必须是同一元素,例子中表示选择了与h1在同一父元素下且与h1是同级的p元素 |
| 伪类选择器 | :active,:focus,:hover,:link,:visited,:first-child,:lang | 依次是为激活的元素添加样式;为拥有键盘输入焦点的样式添加样式;为鼠标悬浮在上方时元素添加样式;为未被访问的链接添加样式;为已经被访问的链接添加样式;为元素的第一个子元素添加样式;为带有指定lang属性的元素添加样式 |
CSS3中新增的伪类和伪元素:
- 伪类元素:
| 选择器名称 | 例子 | 说明 |
|---|---|---|
| :first-of-type | p:first-of-type | 众多同级p元素选取第一个p元素 |
| :last-of-type | p:last-of-type | 众多同级p元素选取最后一p元素 |
| :only-of-type | p:only-of-type | 两个相同div下,div1中只有一个p元素,div2中有多个p元素,则该选择器会选择div1中的p元素,因为div1中有唯一的p元素 |
| :only-child | p:only-child | (IE8以前不支持)选择p元素是其父级的唯一子元素,div下有多个p元素,第一个p元素下面没有包含其他元素,但是其他p元素下面包含其他如span等元素,则选择没有包含子元素的p元素 |
| :nth-child(n) | p:nth-child(2) | (IE8以前不支持)选择p元素的父元素下面的第二个子元素,比如p元素有四个同级元素,p元素位于第二个位置,则例子中就会选择这个p元素 |
| :last-child | p:last-child | p元素的父级的的最后一个子p元素 |
- 伪元素:
| 选择器名称 | 例子 | 说明 |
|---|---|---|
| :root | :root | 选取文档的根元素 |
| :empty | p:empty | 选取文档中没有任何子集的p元素,即选取 |
| :enabled | input:enabled | 选择已经启用的input元素 |
| :disabled | input:disabled | 选择禁用的input元素 |
| :target | $news:target | 选择当前活动的且id名为news的元素 |
| :checked | input:checked | 选择已经被选中的input元素 |
| :not(selector) | :not(p) | 选择不是p元素的所有元素 |
| ::selection | ::selection | 选择被用户选中或者高亮状态的部分 |
| :out-of-range | #num:out-of-range | 设置限制范围之外的样式,比如id为num的input中输入最大最小值之后,超过这个值使用样式 |
| :in-range | #num:in-range | 设置在限制范围以内的样式 |
| :read-write | :read-write | 设置可读可写的元素的样式 |
| :read-only | #num:read-only | 与readonly属性结合使用,设置只读样式 |
| :optional | :optional | 用于匹配可选的输入元素 |
| required | :required | 用于匹配设置了required属性的元素 |
| :valid | :valid | 用于匹配输入合法的元素 |
| :invalid | :invalid | 用于匹配输入不合法的元素 |
层叠与特殊性
- 层叠
在样式表中要寻找同一个元素,可能会有两个或者多个规则,CSS通过层叠处理这个冲突;层叠是因为浏览器中对多个样式的来源进行了叠加,最终确认结果的过程。css的样式来源可能是内联、内部样式、外链样式、浏览器默认样式、用户自定义样式,层叠给每个规则分配一个重要度,这个重要度类似于我们选择器中所说的权重,重要度越大,样式优先级越高,会被优先使用。
-
层叠的重要度次序如下:(重要度依次递减)
- 标有!important的用户样式
- 标有!important的作者样式
- 作者样式
- 用户样式
- 浏览器/用户代理应用的样式
-
特殊性
为了计算规则的特殊性,给每种选择器度分配一个数字值,将规则的每个选择器的值进行叠加,计算出规则的特殊性。其实我更喜欢用权重来进行计算,我把元素选择器的权重设为1,类选择器的权重设为10,id选择的权重设为100,并可进行叠加,权重越高,优先级越高。如一个结合选择器 .class选择器名称 p{}则我认为这个结合选择器的权重是10+1=11,若另一个结合选择器#Id选择器名称 p{}则我认为这个结合选择器的权重为100+1=101,则后面这个结合选择器的优先级更高;
规划、组织、维护样式表
为了便于文档样式维护,最好把样式表划分为几大块,整体文档结构应该类似于下面这样:
-
一般性样式
- 主体样式
- reset样式
- 链 接
- 标 题
- 其他元素
-
辅助样式
- 表单
- 通知和错误
- 一致的条目
-
页面结构
- 标题、导航、页脚
- 布局
- 其他页面元素
-
页面组件
- 各个页面
- 各个页面
-
覆盖样式
- 设置需要特定样式的元素
另外为了后期方便维护与查看,应该为代码添加注释,避免长时间以后忘记自己写的代码;如果要压缩代码,则可以删除注释,优化样式表,较小文件的大小,有利用较少对带宽的占用,加快网页加载速度。
浏览器对CSS的支持
- CSS 1.0
- CSS 2.0
- CSS 3.0